基本实现
在前 LLM 时代,打字机效果主要服务于视觉设计,markdown 主要用来生成静态页面。但随着近些年来 LLM 井喷式的爆发,这两点结合起来成为了 AI Chat App 的标配功能。本文中我们会探讨如今如何将这两点应用于 LLM 输出的渲染处理上,并使用原生 JavaScript 从 0 开始构建一个 LLM 输出渲染的解决方案。
右边展示了一个不加任何处理渲染 LLM 输出的样例,在前端用 fetchLLM() 模拟了 LLM 的返回。在实际的场景中,LLM 的返回是使用 Event Stream 协议分段发送的,并且格式默认为 markdown 格式。我们异步地读取了大模型的返回,并逐步把它的文本追加在 #output 元素上。
迎面而来的问题有两个:
- markdown 渲染是必须的
- 现在的输出看起来很僵硬,能否让吐字的过程更平滑一些
要做到 markdown 的渲染相当容易,市面上常见的开源库有三个:
remark & rehype:基于 AST 操作 markdown。AST 具有相当大的灵活性,正因如此,react 社区中流行的react-markdown才选择了这一技术栈,它实现了markdown AST ⭢ JSX这一转换markdown-it:基于扁平的 tokens 结构而非 AST 操作 markdown,是 VitePress 的底层库marked:和markdown-it类似基于扁平的 tokens,主打轻量高性能
本文的例子中选用 remark & rehype 的组合来做到 markdown 到 HTML 的转换,这一组合灵活性更高,对 react 技术栈贴合性也更好些。右侧的第二个 Tab 展示了引入它之后的效果。
markdown 被正确地渲染成了 HTML,一切好像有模有样,但是仔细看会发现,文本的显现是一顿一顿的,大模型的真实返回总是不太均匀,时长时短,且 chunk 与 chunk 之间的时间间隔也不均匀。从视觉感受上来说,这种直接渲染的方式不够优雅。
import { fetchLLM } from './fetch-llm.js';
const output = document.getElementById('output');
for await (const chunk of fetchLLM()) {
output.textContent += chunk;
}export async function* fetchLLM() {
const responses = [
'# 旅行准备清单\n\n',
'**在开始一次长途旅行之前,确保你已经准备好了所',
'有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**\n\n旅行前需要准备的事项:\n\n',
'- 检查护照和签证是否有效\n',
'- 准备充足的现金和信用卡\n- 打包适合当地气候的衣物\n- 预订住宿和交通工具\n- 购买旅行保险\n- 准备常用药品和个人护理用品\n\n提前做好这些准备,可以有效避免旅途中的各种突发状况。',
];
for (const chunk of responses) {
yield new Promise(resolve => setTimeout(() => resolve(chunk), 500));
}
}加个动画试试?
在前端开发里,元素的 fade-in 和 fade-out 是很常用的手段,它会让内容的出现和消失显得不那么跳跃,那如果我们给每次新渲染的 chunk 加上动画渐显效果,会不会效果就会还可以?
一个前提是,需要注意到之前的实现每次都是用 innerHTML 全量覆盖原本渲染好的内容,这样会导致每次 DOM 都会新建,每次增加新的 chunk,原本出现的文本也会被应用一次动画效果,这显然不行。在 react 中,它的 diff 算法自动为我们规避了这个问题,但在 VanillaJS 中需要自己解决。好在一个名为 morphdom 库可以帮我们解决这个问题,它做了和 react 类似的事情,帮我们自动 diff 了变更的 DOM,只会修改这些 DOM 元素。
在实际转换成 HTML 字符串之前,我们可以通过 rehype 插件操作 HTML AST,给新出现的词语文本加上 fade-in class,从而让这些文本出现得不那么突兀。这个效果应该以词(word)为粒度去添加,而不是简单的 chunk 粒度。设想一种场景,LLM 的返回的增长序列为:
I am
I am a tea
I am a teacher.这是一个单行的文本,会被编译成一个单独的 <p> 标签。每一次渲染,这个 <p> 标签都会因为有新的内容加入而被销毁重新渲染,如果 fade-in 这个 class 加在了 <p> 上或者仅仅是把所有文本包裹一层,如果渲染到 I am a teacher.,前面已经出现过的 I am a tea 还是会过一遍动画效果,即使我们使用了 html diff 渲染的方案。这显然不是个好的视觉体验。
因此,我们理想的渲染过程应该是(这里由于长度原因隐去了 span 的 class):
<p><span>I</span><span> </span><span>am</span></p>
<p><span>I</span><span> </span><span>am</span><span> </span><span>a</span><span> </span><span>tea</span></p>
<p><span>I</span><span> </span><span>am</span><span> </span><span>a</span><span> </span><span>teacher</span><span>.</span></p>这里其实会有一个小问题,在输出第二个 chunk 的时候,tea 会有一个动画效果,但是在输出第三个 chunk 的时候,会产生一个新的分词 teacher 替代原本的 tea,这就使得 tea 这三个字母重新执行了一次动画。这是加上动画时遇到的一个老大难题,对 HTML 文本做 diff,只对新增的部分做分词似乎可以解决这个问题,但我觉得这样实现起来过于复杂了,这里不做讨论。
逐字符地包裹 <span> 似乎是一种可行的方案,但这样会让 DOM 元素几何倍增,对渲染会造成更大的压力。总而言之,针对「词」添加动画,是一种权衡之后的选择。
借助 Intl.Segmenter 分词操作很容易做到:
const text = "I am a teacher.";
const segmenter = new Intl.Segmenter('en', { granularity: 'word' });
const segments = segmenter.segment(text);
const result = [];
for (const { segment } of segments) {
result.push(segment);
}
console.log(result); // ['I', ' ', 'am', ' ', 'a', ' ', 'teacher', '.']实现一个名为 rehypeStreamAnimated 的插件,这个插件做的事就是遍历 HTML 的节点,找到其中的纯文本部分,分词,并为它们包裹上 <span class="fade-in">。
右侧是完整实现的 Demo,你会发现前半部分加粗的文本内容执行动画了两次,这是因为最开始的加粗语法没有闭合,remark 无法将它视为一个加粗的部分,于是当成了纯文本处理,后来加粗的语法闭合之后,这一整块内容才被 <strong> 包裹。由于 <strong> 是新元素,自然里面的所有元素都会执行一遍动画效果。这也是我们当前实现的一个瑕疵。
但无论如何,现在的效果比不加动画时好多了。我在查看 Lobe Chat 源码的时候学到了这种做法。
import { unified } from "https://esm.sh/unified@11";
import remarkParse from "https://esm.sh/remark-parse@11";
import remarkRehype from "https://esm.sh/remark-rehype@11";
import rehypeStringify from "https://esm.sh/rehype-stringify@10";
import { fetchLLM } from './fetch-llm.js';
import { rehypeStreamAnimated } from './plugin.js';
import { render } from './render.js';
async function mdToHTML(markdown) {
const file = await unified()
.use(remarkParse) // markdown -> md AST
.use(remarkRehype) // md AST -> html AST
.use(rehypeStreamAnimated) // html AST -> html AST with animation
.use(rehypeStringify) // html AST -> html string
.process(markdown);
return String(file);
}
let md = '';
const output = document.getElementById('output');
for await (const chunk of fetchLLM()) {
md += chunk;
const html = await mdToHTML(md);
render(output, html);
}import morphdom from "https://esm.sh/[email protected]";
function render(container, html) {
const temp = document.createElement('div');
temp.innerHTML = html;
morphdom(container, temp, {
// 保留 container 本身,不替换
childrenOnly: true
});
}import { visit } from "https://esm.sh/unist-util-visit@5";
export function rehypeStreamAnimated() {
return (tree) => {
visit(tree, 'element', (node) => {
if (['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'li', 'strong'].includes(node.tagName) && node.children) {
node.children = processChildren(node.children);
}
});
};
}
// 递归处理所有子节点
function processChildren(children) {
const newChildren = [];
for (const child of children) {
// 如果是 Text Node,则按词拆分并包裹 span
if (child.type === 'text') {
const segmenter = new Intl.Segmenter(navigator.language, { granularity: 'word' });
const segments = segmenter.segment(child.value);
for (const segment of segments) {
const word = segment.segment;
if (word.trim() === '') {
// 空白符无需处理
newChildren.push({ type: 'text', value: word });
} else {
newChildren.push({
type: 'element',
tagName: 'span',
properties: { className: ['fade-in'] },
children: [{ type: 'text', value: word }]
});
}
}
} else if (child.type === 'element' && child.children) {
// 如果当前元素已经是 fade-in 的 span,则不再递归处理,防止嵌套
if (
child.tagName === 'span' &&
child.properties &&
Array.isArray(child.properties.className) &&
child.properties.className.includes('fade-in')
) {
newChildren.push(child);
} else {
newChildren.push({ ...child, children: processChildren(child.children) });
}
} else {
newChildren.push(child);
}
}
return newChildren;
}export async function* fetchLLM() {
const responses = [
'# 旅行准备清单\n\n',
'**在开始一次长途旅行之前,确保你已经准备好了所',
'有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**\n\n旅行前需要准备的事项:\n\n',
'- 检查护照和签证是否有效\n',
'- 准备充足的现金和信用卡\n- 打包适合当地气候的衣物\n- 预订住宿和交通工具\n- 购买旅行保险\n- 准备常用药品和个人护理用品\n\n提前做好这些准备,可以有效避免旅途中的各种突发状况。',
];
for (const chunk of responses) {
yield new Promise(resolve => setTimeout(() => resolve(chunk), 500));
}
}自适应输出速度
前面的实现是给出现的文本整体添加过渡动画,没有使用到打字机效果,就个人来说,我觉得这种效果是完全可接受的,过渡动画已经大幅削弱了文本出现的卡顿感,但市面上主流的 AI Chat 应用基本还是都在使用打字机效果。
让我们先做一个简单的打字机效果实现,如右侧所示,不管 LLM 的实际输出速度如何,设定每 40ms 让渲染的 markdown string 长度加 1。
通过观察 fetchLLM() 的实现可以得知,一共有 5 个 chunk,每 500ms 发送一次,所以实际上 2500ms 就将所有的文本发送完成了。这些字符一共 184 个,我们固定速度输出完成,花费了 184 * 40 = 7360ms,几乎是实际返回三倍。那调短 setInterval 的间隔呢?如果输出过快,确实能让实际渲染完成的时间跟上接口实际返回的时间,但这样会导致 chunk 与 chunk 渲染之间有明显的时间差,使用打字机效果的意义就被削弱了。LLM 的参数、用户的网络情况都会影响接口返回速度,所以很难找到一个唯一恰当的速度。解决方式就是使用一个能让输出速度变平滑的策略,让打字速度「该快的时候快,该慢的时候慢」。
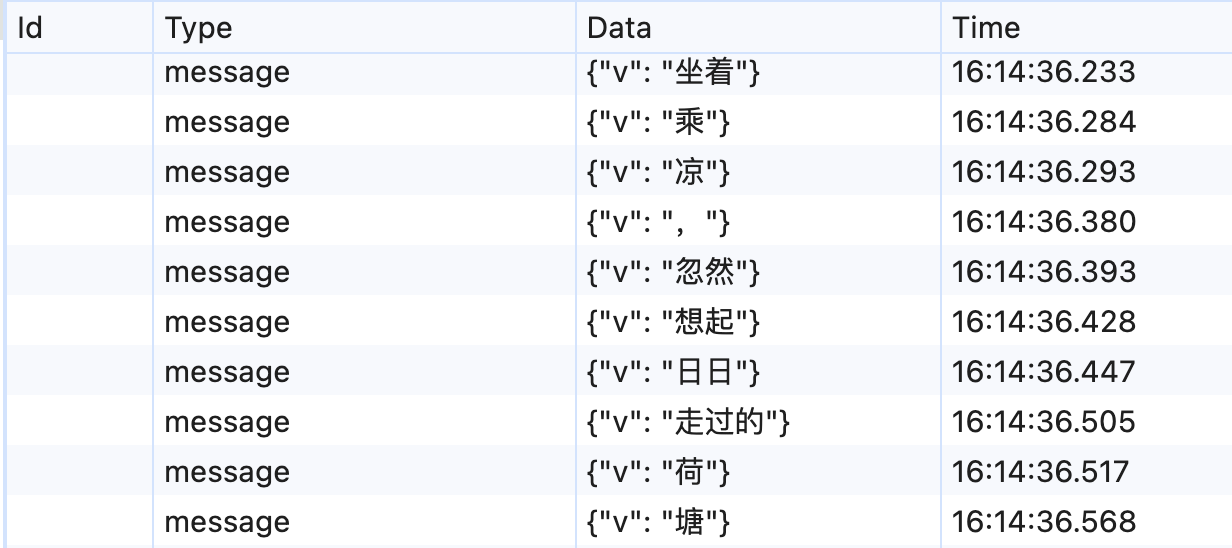
Cherry Studio 中的实现 很具有借鉴价值。将收到还未渲染的内容分词后放入一个队列,每一帧在现有 markdown 上追加
每次以词为单位输出避免了输出单个字符的僵硬感,队列长度除以 5 的策略则做到了大模型输出内容少的时候打字慢、大模型输出内容多的时候打字快的效果。右侧的第二个 Tab 展示了应用这一策略后的效果。通过观察右下角实时统计看到输出速度的实时变化。
不过现在的输出好像还是太快了,大部分时候每帧还是只输出一词,并且出现了等待返回的情况。我推测应该是模拟的 event stream 还是不太贴合现实场景,于是查看了一下 deepseek 的对话返回情况。一方面,deepseek LLM 的实际返回要更快一些,fetchLLM() mock 的数据平均每个字符返回时间是 184 / 2500 = 0.0736ms,而 deepseek 接口返回每个字符大概耗时是 0.04ms;另外,它的每段返回是快而小的,每个 chunk 几乎都是词甚至字的粒度,间隔几乎都小于 100ms,不像我们的 chunk 慢而长。这使得渲染流程少有看起来停顿的时刻。
let md = '';
let display = '';
setInterval(async () => {
if (display.length < md.length) {
display += md[display.length];
const html = await mdToHTML(display);
render(output, html);
}
}, 40);
const output = document.getElementById('output');
for await (const chunk of fetchLLM()) {
for (const char of chunk) {
md += char;
}
}export async function* fetchLLM() {
const responses = [
'# 旅行准备清单\n\n',
'**在开始一次长途旅行之前,确保你已经准备好了所',
'有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**\n\n旅行前需要准备的事项:\n\n',
'- 检查护照和签证是否有效\n',
'- 准备充足的现金和信用卡\n- 打包适合当地气候的衣物\n- 预订住宿和交通工具\n- 购买旅行保险\n- 准备常用药品和个人护理用品\n\n提前做好这些准备,可以有效避免旅途中的各种突发状况。',
];
for (const chunk of responses) {
yield new Promise(resolve => setTimeout(() => resolve(chunk), 500));
}
}增量渲染
常见的 markdown 渲染库基本都是服务于一次性的静态内容生成,没有增量渲染的能力。我们之前的实现里也可以看出来,每次要渲染新的内容,都要把整个 markdown 字符串执行一下转换,执行的频次几乎是逐帧的。从性能上考量,可以有更好的实现方式。
一个有效的做法是按块(block)转换,每次只用最新的块作为参数传入 mdToHTML()。还记得之前提到的 marked 和 markdown-it 这两个库吗,它们和 remark 不同,不是将 markdown 转化为 AST,而是将其转化为扁平结构处理。这一扁平的结构被叫做 tokens,而每个 token 子项就是一个块。
我们选用 marked 来实现,这也是 Streamdown 和 @ant-design/x-markdown 的选择。相比 markdown-it 它的体积更小一些。
marked 提供了一个 lexer 函数,可以将 markdown 解析为 tokens 数组:
# 旅行准备清单
**在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**
旅行前需要准备的事项:
- 检查护照和签证是否有效
- 准备充足的现金和信用卡
- 打包适合当地气候的衣物
- 预订住宿和交通工具
- 购买旅行保险
- 准备常用药品和个人护理用品
提前做好这些准备,可以有效避免旅途中的各种突发状况。marked.lexer
[
{ "type": "heading", "depth": 1, "text": "旅行准备清单" },
{ "type": "paragraph", "text": "..." },
{ "type": "space", "raw": "\n\n" },
{ "type": "paragraph", "text": "..." }
{ "type": "space", "raw": "\n\n" },
{ "type": "list", "ordered": false, "items": [/* ... */] },
{ "type": "space", "raw": "\n\n" },
{ "type": "paragraph", "text": "..." }
]点击展开/收起完整的 tokens 结构
[
{
"type": "heading",
"raw": "# 旅行准备清单\n\n",
"depth": 1,
"text": "旅行准备清单",
"tokens": [
{
"type": "text",
"raw": "旅行准备清单",
"text": "旅行准备清单",
"escaped": false
}
]
},
{
"type": "paragraph",
"raw": "**在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**",
"text": "**在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**",
"tokens": [
{
"type": "strong",
"raw": "**在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**",
"text": "在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。",
"tokens": [
{
"type": "text",
"raw": "在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。",
"text": "在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。",
"escaped": false
}
]
}
]
},
{
"type": "space",
"raw": "\n\n"
},
{
"type": "paragraph",
"raw": "旅行前需要准备的事项:",
"text": "旅行前需要准备的事项:",
"tokens": [
{
"type": "text",
"raw": "旅行前需要准备的事项:",
"text": "旅行前需要准备的事项:",
"escaped": false
}
]
},
{
"type": "space",
"raw": "\n\n"
},
{
"type": "list",
"raw": "- 检查护照和签证是否有效\n- 准备充足的现金和信用卡\n- 打包适合当地气候的衣物\n- 预订住宿和交通工具\n- 购买旅行保险\n- 准备常用药品和个人护理用品",
"ordered": false,
"start": "",
"loose": false,
"items": [
{
"type": "list_item",
"raw": "- 检查护照和签证是否有效\n",
"task": false,
"loose": false,
"text": "检查护照和签证是否有效",
"tokens": [
{
"type": "text",
"raw": "检查护照和签证是否有效",
"text": "检查护照和签证是否有效",
"tokens": [
{
"type": "text",
"raw": "检查护照和签证是否有效",
"text": "检查护照和签证是否有效",
"escaped": false
}
]
}
]
},
{
"type": "list_item",
"raw": "- 准备充足的现金和信用卡\n",
"task": false,
"loose": false,
"text": "准备充足的现金和信用卡",
"tokens": [
{
"type": "text",
"raw": "准备充足的现金和信用卡",
"text": "准备充足的现金和信用卡",
"tokens": [
{
"type": "text",
"raw": "准备充足的现金和信用卡",
"text": "准备充足的现金和信用卡",
"escaped": false
}
]
}
]
},
{
"type": "list_item",
"raw": "- 打包适合当地气候的衣物\n",
"task": false,
"loose": false,
"text": "打包适合当地气候的衣物",
"tokens": [
{
"type": "text",
"raw": "打包适合当地气候的衣物",
"text": "打包适合当地气候的衣物",
"tokens": [
{
"type": "text",
"raw": "打包适合当地气候的衣物",
"text": "打包适合当地气候的衣物",
"escaped": false
}
]
}
]
},
{
"type": "list_item",
"raw": "- 预订住宿和交通工具\n",
"task": false,
"loose": false,
"text": "预订住宿和交通工具",
"tokens": [
{
"type": "text",
"raw": "预订住宿和交通工具",
"text": "预订住宿和交通工具",
"tokens": [
{
"type": "text",
"raw": "预订住宿和交通工具",
"text": "预订住宿和交通工具",
"escaped": false
}
]
}
]
},
{
"type": "list_item",
"raw": "- 购买旅行保险\n",
"task": false,
"loose": false,
"text": "购买旅行保险",
"tokens": [
{
"type": "text",
"raw": "购买旅行保险",
"text": "购买旅行保险",
"tokens": [
{
"type": "text",
"raw": "购买旅行保险",
"text": "购买旅行保险",
"escaped": false
}
]
}
]
},
{
"type": "list_item",
"raw": "- 准备常用药品和个人护理用品",
"task": false,
"loose": false,
"text": "准备常用药品和个人护理用品",
"tokens": [
{
"type": "text",
"raw": "准备常用药品和个人护理用品",
"text": "准备常用药品和个人护理用品",
"tokens": [
{
"type": "text",
"raw": "准备常用药品和个人护理用品",
"text": "准备常用药品和个人护理用品",
"escaped": false
}
]
}
]
}
]
},
{
"type": "space",
"raw": "\n\n"
},
{
"type": "paragraph",
"raw": "提前做好这些准备,可以有效避免旅途中的各种突发状况。",
"text": "提前做好这些准备,可以有效避免旅途中的各种突发状况。",
"tokens": [
{
"type": "text",
"raw": "提前做好这些准备,可以有效避免旅途中的各种突发状况。",
"text": "提前做好这些准备,可以有效避免旅途中的各种突发状况。",
"escaped": false
}
]
}
]除了 space 类型的 token,每个 token 都对应着一个块级 html 元素。每次有新增内容需要渲染时,都遍历一下新的 tokens 和旧的 token 做对比,如果 raw(这个 token 对应的 markdown 文本)发生变化,说明需要重新转换这个块为 html。我们把这个过程提取到 diffRender() 函数中,用它替换掉原本的 mdToHTML(display).then(html => render(output, html)),右侧是最终的实现。
在实际展示的例子中,我为变动的 html 块添加了高亮效果,可以看到每次有新增内容,别的部分都不会重新转换一遍。在开发者工具里可以看到这个效果的具体实现。
let md = '';
let display = '';
let streamDone = false;
let rafId = null;
const queue = [];
const htmlBlocks = [];
let prevTokens = [];
async function diffRender(md) {
const tokens = marked.lexer(md);
for (let i = 0; i < tokens.length; i++) {
const token = tokens[i];
const prevToken = prevTokens[i];
// 如果块的 raw 内容未变,则跳过渲染
if (prevToken && prevToken.raw === token.raw) {
continue;
}
const htmlBlock = await mdToHTML(token.raw);
if (prevToken) {
// 块内容变更,重新渲染该块
htmlBlocks[i] = htmlBlock;
} else {
// 新增块,渲染该块并追加
htmlBlocks.push(htmlBlock);
}
render(output, htmlBlocks.join(''));
}
prevTokens = tokens;
}
rafId = requestAnimationFrame(function loop() {
if (queue.length === 0) {
if (streamDone) {
cancelAnimationFrame(rafId);
} else {
rafId = requestAnimationFrame(loop);
}
return;
}
// 渲染长度为 queue 长度的 1/5,至少 1 个
const nextRenderCount = Math.max(1, Math.floor(queue.length / 5));
const nextRenderSegments = queue.splice(0, nextRenderCount);
display += nextRenderSegments.join('');
diffRender(display);
rafId = requestAnimationFrame(loop);
});
const segmenter = new Intl.Segmenter(navigator.language, { granularity: 'word' });
const output = document.getElementById('output');
for await (const chunk of fetchLLM()) {
const segments = segmenter.segment(chunk);
queue.push(...Array.from(segments).map(s => s.segment));
}
streamDone = true;export async function* fetchLLM() {
const responses = [
'# 旅行准备清单\n\n',
'**在开始一次长途旅行之前,确保你已经准备好了所',
'有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**\n\n旅行前需要准备的事项:\n\n',
'- 检查护照和签证是否有效\n',
'- 准备充足的现金和信用卡\n- 打包适合当地气候的衣物\n- 预订住宿和交通工具\n- 购买旅行保险\n- 准备常用药品和个人护理用品\n\n提前做好这些准备,可以有效避免旅途中的各种突发状况。',
];
for (const chunk of responses) {
yield new Promise(resolve => setTimeout(() => resolve(chunk), 500));
}
}处理未闭合语法
由于输出是流式的,markdown 的语法会在输出尚未完成的时候出现未闭合的情况。就像之前的例子所展示的,当第二个 chunk 出现,还在等待第三个 chunk 时,**在开始一次长途旅行之前,确保你已经准备好了所 这句话即使有前缀的两个星号,由于是未闭合的,因此只能被识别为普通文本:
<p>**在开始一次长途旅行之前,确保你已经准备好了所</p>直到后面出现了两个星号,使它成为了完整闭合的粗体语法,我们才得到:
<p><strong>在开始一次长途旅行之前,确保你已经准备好了所有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。</strong></p>从视觉上看,先出现又消失的星号是一种有点烦人的文本噪声。一个妥善的解决方式是,当检测到 ** 前缀的时候,自动为其添加后缀的两个星号,使其闭合,然后再进行 mdToHTML 操作,这样我们就能先得到 <p><strong>在开始一次长途旅行之前,确保你已经准备好了所</strong></p>。除了视觉效果上好了很多,由于 DOM 变得更稳定,我们如果想加上动画效果的话,效果也会更好一些。
markdown 语法还是比较复杂的,除了加粗、斜体这种简单的闭合结构,还有图片、链接、表格这种相对难以处理的的结构。这里我们为了简单就只以粗体为例了。
依然是从 token 维度动手,在将 token 的内容转换为 html 之前,先对其做判断,通过正则匹配(/(\*\*)([^*]*?)$/)的方式查看当前文本是否以 ** + 任意文本结尾。如果符合这一正则,就说明当前内容需要补全了吗?其实还有一个漏洞,如果文本为:
**I am** fine.它包含了已闭合的加粗语法,但其实也能匹配上前文中的正则表达式。所以还需要做一层额外的保险,如果这段文本中的双星号总数是奇数,才说明需要进行补全。
在 mdToHTML 操作之前做补全操作,把补全后的文本交给 remark,就能得到闭合的 markdown 结构了。
这里只处理了最简单的情况,实际的补全操作要考虑的情况相当之多,Streamdown 和 Ant Design X Markdown 在这些操作上花了不少功夫。
// 补全未闭合语法, 只处理了加粗
function handleIncompleteMarkdown(md) {
if (/(\*\*)([^*]*?)$/.test(md)) {
const asteriskPairs = (md.match(/\*\*/g) || []).length;
// 如果匹配到的 `**` 为奇数个, 进行补全
if (asteriskPairs % 2 === 1) {
md += '**';
}
}
return md;
}
async function diffRender(md) {
// ...
const safeRaw = handleIncompleteMarkdown(token.raw);
const htmlBlock = await mdToHTML(safeRaw);
// ...
}export async function* fetchLLM() {
const responses = [
'# 旅行准备清单\n\n',
'**在开始一次长途旅行之前,确保你已经准备好了所',
'有必需的物品和文件,这样可以让你的旅途更加顺利和愉快。**\n\n旅行前需要准备的事项:\n\n',
'- 检查护照和签证是否有效\n',
'- 准备充足的现金和信用卡\n- 打包适合当地气候的衣物\n- 预订住宿和交通工具\n- 购买旅行保险\n- 准备常用药品和个人护理用品\n\n提前做好这些准备,可以有效避免旅途中的各种突发状况。',
];
for (const chunk of responses) {
yield new Promise(resolve => setTimeout(() => resolve(chunk), 500));
}
}