《Java编程思想》读书笔记 —— 第11章 持有对象
Back前面的章节都更重视理论一些,”持有对象“这一章却有点不一样,感觉更重视的是应用,也就是让读者学会使用Java中容器类的使用方法。关于容器类更加深层次的内容,主要是在第17章”容器深入研究“中叙述。即使是这样,这章的篇幅还是比前面都长不少……希望能概括的不错吧。
持有对象,根据字面意思来理解,应该是如何保存对象的意思。当我们不知道会需要创建多少对象、需要很好地统一管理很多对象的时候,依靠创建命名的引用来持有每一个对象是不切实际的。幸好Java中提供给我们很多可供选择的容器类,其中的基本类型是List,Set,Queue,Map,也称为集合类。本章主要叙述这些类的使用方法。
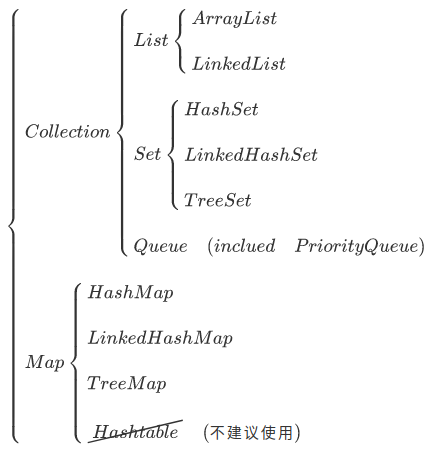
书本的总结部分有着下面这张图,展示了容器之间的关系。实线框表示普通类,虚线框表示接口,空心箭头表示接口的实线,实心箭头表示某个类可以生成箭头所指向类的对象。

上面提到的四种基本集合类中,List,Set,Queue是Collection类型,而Map是另一种独立的类型,至于Map指向Collection实心箭头,我的理解是Map类的对象可以使用keySet()、entrySet()方法产生Set,这是Collection类型。
泛型和类型安全的容器
当一个容器不使用泛型的时候,默认它接受Object型的对象,也就是任何对象都可以存入容器,这种最大程度的宽松往往会导致一些麻烦。
在书中给出的例子中,有两个不相关的类Apple和Orange,将它们的对象都存入了一个ArrayList中,因为ArrayList容器没有使用泛型限制存入对象的类型,所以,当试图调用一个Apple类拥有但是Orange类没有的方法时,就会出现运行时出错。但是如果使用了泛型,规定只有Apple类的对象才可以存入这个ArrayList,那么当试图存入一个Orange对象时,在编译时就会报错,避免酿成运行时才出错的后果。
通过使用泛型,就可以在编译器防止将错误类型的对象防止到容器中(编译时错误总好过运行时才发生错误)。
向上转型也可以作用与泛型,比如Apple类的子类也可以存入ArrayList<Apple>容器中。
基本概念
Java容器类分为两个不同的概念,分别是Collection和Map
- Collection: 一个独立元素的序列,这些元素都服从一条或多条规则。
- Map: 一组成对的”键值对“对象,允许你使用键来查找值。
四种基本类型List,Set,Queue,Map可以进行如下的分类:
当使用一个具体的容器对象的时候,往往建议将它向上转型成为接口来使用,例:
List<Apple> apples = new ArrayList<Apple>();这样当需要修改使用的容器对象,只需要在创建处修改就可以了。
但是由于向上转型是一种”窄化“处理,所以在有些情况下这种方式并不能使用,譬如List中没有包括LinkedList中的特有方法,Map接口中也没包括TreeMap的特有方法。
所有的Collection容器对象也都可以向上转型为Collection类型,这个接口中包括了序列对象常用的方法,比如add,addAll,clear ,size,remove,isEmpty,iterator,toArray,hashCode,equals,contains,containsAll。
且所有的Collection都可以使用Foreach语法遍历:
Collection<Integer> c = new ArrayList<Integer>();
for(int i=0; i<10; i++)
c.add(i);
for(Integer i : c)
System.out.print(i + " ");添加一组元素
使用add方法向Collection中加入元素固然可以,但是当我们需要向Collection中添加一组元素的时候,就需要效率更高的手段了。书中介绍了向Collection中添加一组元素的两种方式:
-
collection.addAll()和Arrays.asList()方法配合,
Arrays.asList()接收一个数组对象或者是一个用逗号分隔的元素列表,并将其转换成一个List对象。javaInteger[] moreInts = {1, 2, 3, 4, 5}; collection.addAll(Arrays.asList(moreInts)); -
Collections.addAll()方法,接收一个
Collection对象,再接收一个数组或者是一个用逗号分隔的元素列表,将其添加到Collection对象中。javaCollections.addAll(collection, 1, 2, 3, 4, 5);
两种方法中Collections.addAll()方法更快,且创建一个空Collection对象再向其中添加元素的方式更方便,所以优先选择Collections.addAll()方法。
使用Arrays.asList()方法的注意事项
书中给出了如下继承关系的一组类:
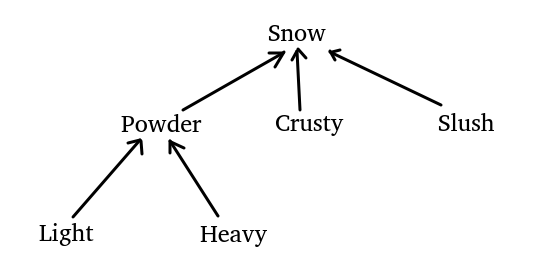
// List<Snow> snow = Arrays.asList(new Light(), new Heavy())
// Arrays.asList()会创建List<Powder>而非List<Snow>,所以会出现编译错误
// 正确方式:使用显式类型参数说明
List<Snow> snow = Arrays.<Snow>asList(new Light, new Heavy())容器的打印
容器是可以直接打印的,Collection和Map打印出的格式如下:
[rat, cat, dog, dog] // Collection的打印格式
{dog=Spot, cat=Rags, rat=Fuzzy} // Map的打印格式- HashSet,HashMap:乱序,最快
- LinkedHashSet,LinkedHashMap:打印顺序为存入顺序
- TreeSet,TreeMap:默认升序
List
List在Collection的基础上添加了大量的方法,允许向其中插入和删除元素。
ArraysList随机访问更快,LinkedList插入和删除更快。
常用方法
-
get(n) : 得到第n个对象
-
indexOf(p) : 得到对象p的索引位置
-
remove(p) : 删除第一个p对象,也可以放入索引值,表示删除第几个元素
-
removeAll(collection) : 删除collection中包含的所有元素
-
subList(1, 4) : 获取[1, 4)的子串
-
cotainsAll(sub) : 判断是否包含sub中的所有元素
-
list1.retainAll(list2) : 将list1和list2的交集放置在list1中
-
clear() : 清空List
-
set(2, p) : 将第2个位置的对象换成p对象,以下两种方式并没有区别:
javaInteger p = new Integer(2); list.set(2, p); // 之后p指向其他对象,对list也不会有影响 list.set(2, new Integer(2)); -
toArray() :如果不加参数,默认产生的是Object类型数组,传递目标类型数据才可产生指定类型的数组
javaObject[] array = list.toArray(); Integer[] array = list.toArray(new Integer[0]);
Collections工具类中的方法:
- Collections.sort(list) : 排序
- Collections.shuffle(list, rand) : 按照参数中的随机数对象打乱list
在第13节的时候也讲到了一条有关Collections.shuffle()方法的注意事项:
Random rand = new Random();
Integer[] a = {1, 2, 3, 4, 5};
List<Integer> list1 = new ArrayList<Integer>(Arrays.asList(a));
Collections.shuffle(list1, rand);
List<Integer> list2 = Arrays.asList(a);
Collections.shuffle(list2, rand);其实代码和Collections.shuffle()方法本身的关系倒不是很大的样子,值得注意的是list1和list2初始化方式的不同。
- list1的初始化使用了
ArrayList的构造器,这将创建一个a数组的副本,在打乱list1之后数组本身的顺序并不会受到影响。 - list2的初始化没有用到
ArrayList的构造器,这个操作没有创建a数组的副本,打乱list2之后数组本身的顺序和list2中元素顺序是完全相同的,数组内容也会被打乱
将数组转化成List时,需不需要将底层数组改变,这是需要选择的。
LinkedList
LinkedList也实现了List接口,相比ArrayList更善于对象的插入和移除操作,此外,LinkedList提供了一些额外的、用于实现栈、队列和双端队列的方法。
-
getFirst(), Element()和peek():三者均返回链表头部元素,但是当链表为空时,前两个返回
NoSuchElementException异常,而peek()返回null -
remove(), removeFirst()和poll():移除并返回链表的头,链表为空时,前两个返回
NoSuchElementException异常,而poll()返回null -
addFirst(), addLast():将元素插在列表头部、尾部
-
offer():应该是为了实现
Queue接口 ,向队尾添加元素 -
pop(): 删除末尾(栈顶)元素,为了实现
Deque接口,也可用于Stack实现,队列为空返回null
Stack和Queue
stack和queue是两种基本的数据结构,其实都可以使用LinkedList来实现。
Stack
在Java中已经实现了栈,可以使用导入java.util.Stack来使用,这个Stack是继承自Vector类来实现的,由于设计上的失误,这个栈并不令人满意,所以书中更倾向于使用自己使用LinkedList实现的栈:
import java.util.LinkedList;
public class Stack<T> {
private LinkedList<T> strorage = new LinkedList<T>();
public void push(T v) { storage.addFirst(v); }
public T peek() { return storage.getFirst(); }
public T pop() { return storage.removeFirst(); }
public boolean empty() { return storage.isEmpty(); }
public String toString() { return storage.toString(); }
}这里使用的是组合的方式,如果直接继承LinkedList,则会多出很多不需要的方法。
Queue
Queue是一个接口,LinkedList提供了实现这一接口的方法,所以可以将LinkedList向上转型为Queue。
Queue<Integer> queue = new LinkedList<Integer>();PriorityQueue
优先队列,队首的元素始终是优先级最高的元素,也就是说,当使用peek(),poll(),remove(),获取的元素都将是队列中优先级最高的元素。默认的顺序是最小的优先级最高,对于字符串也是字典序最小的优先级最高,至于自定义的类,则需要使用者提供自己Comparator,第17章中会对这种情况进行详细的说明。
下面给出翻转优先级的例子:
priorityQueue = new PriorityQueue<Integer>(list.size(), Collections.reverseOrder);
priorityQueue.addAll(list);也就是在创建对象的时候规定好优先级,再重新添加进原本的list。
Set
Set也是一种Collection,只是行为有所不同,其中的元素互异且唯一,Collection中的方法(add(), remove(), removeAll(), clear() 等)也适用于Set。
目前需要了解的是三种Set之间的区别(其实前面也有介绍):
HashSet使用散列,速度最快,但是乱序LinkedHashSet使用散列,同时也使用一个链表保持元素顺序也是add的顺序TreeSet使用红黑树,会自动排序
Map
1. 基本语法
Map是一个和Collection不同的结构,每个空间存储的是一个键值对,书中给出的检测Random类产生的随机数随机性的代码,我认为是对Map用法的一个相当好的参考:
import java.util.*;
public class Statistics {
public static void main(String[] args) {
Random rand = new Random();
Map<Integer, Integer> m =
new HashMap<Integer, Integer>();
for(int i=0; i<10000; i++) {
int r = rand.nextInt(20);
Integer freq = m.get(r);
m.put(r, freq == null ? 1 : freq + 1);
}
System.out.println(m);
}
}{0=466, 1=508, 2=457, 3=449, 4=470, 5=495, 6=492, 7=517, 8=525, 9=547, 10=482, 11=501, 12=516, 13=521, 14=522, 15=520, 16=534, 17=480, 18=520, 19=478}主要的用法是使用put存入一对数据,使用get(key)得到key对应的value的值。令我不解的是,这里我使用的明明是HashMap,但是输出结果为什么是按照key的大小排好序的?
知乎上找到了解释:
实现是会变的,HashSet的迭代器在输出时“不保证有序”,但也不是“保证无序”。也就是说,输出时有序也是允许的,但是你的程序不应该依赖这一点。
同样的,HashMap依靠ketSet打印结果,输出不保证有序,但是并不是一定无序。
2. 使用复合的泛型
容器之间可以互相组合,生成很强大的数据结构,譬如我们想把一个人和它的多个宠物对应起来:
Map<Person, List<Pet>>3. 使用foreach遍历Map
这里就是使用上面的个人和宠物列表对应的Map,使用foreach对这个结构进行遍历:
for(Person person : petPeople.keySet()) {
System.out.print(person + "has");
for(Pet pet : petPeople.get(person))
System.out.print(" " + pet);
}我们可以通过keySet产生一个由key组成的集合,这是一种Collection,所以可以使用foreach遍历一个HashMap中的所有key。
常用的将Map向Collection转化的方法有以下三种:
public Set<K> keySet()
public Collection<V> values()
public Set<Map.Entry<K, V>> entrySet()
// 使用Entry遍历:Iterator it = map.entrySet().iterator()的方式,利用迭代器遍历
例:
Integer key, value;
Iterator<Map.Entry<Integer, Integer>> it = m.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<Integer, Integer> entry = it.next();
System.out.print(entry.getKey() + "=" + entry.getValue() + ", ");
}迭代器
有关迭代器的使用书中使用了分散的三节来讲述,这里我把它们汇总一下:
迭代器的基本使用
迭代器是一个对象,它的工作是遍历并选择序列中的对象,而客户端程序员不必知道或关心该序列底层的结构。
1. Iterator
是一个只能单向移动的迭代器,方法有:
- iterator(): 可以让容器返回一个
Iterator对象,这个对象准备好返回序列的第一个元素。 - next(): 获取序列中的下一个元素。
- hasNext(): 判断序列中是否还有元素。
- remove(): 将迭代器返回的元素清除(清除由
next()产生的最后一个元素)。
ps: 其实如果不打算修改序列本身,使用foreach语法遍历会更加方便。
2. ListIterator
ListIterator是一个比Iterator拥有更多功能的迭代器,支持双向移动,也可以通过listIterator(n)形式的构造器创建一个一开始就指向列表索引为n处的ListIterator,使用示例如下:
ListIterator<Pet> it = pets.listIterator();
while(it.hasNext())
System.out.print(it.next() + ", " + it.nextIndex() + ", " + it.previousIndex() + "; ");
System.out.println();
// 后向移动
while(it.hasPrevious())
System.out.print(it.previous().id() + " ");
System.out.println();
System.out.println(pets);
it = pets.listItertor(3); // 创建一个初始位置为3的ListIterator其实就是在原本只有“next”的基础上加上了对应的“previous”方法,实现了双向移动。
Collection和Iterator
Collection是描述所有序列容器的共性的根接口。
C++容器没有公共的基类,只能使用Iterator来表示容器之间的共性。但是在Java中,容器既有公共基类,也有迭代器的存在,且这两者是绑定在一起的,只要实现Collection接口就意味着必需实现iterator()方法。
当实现一个不是Collection的外部类的时候,让它去实现Collection接口中的所有方法是十分困难的。这时候我们有两种选择:
- 继承
AbstractCollection类,实现其中的iterator()和size()方法(注意iterator()的返回值是Iterator<T>,书中给出的例子一般都是返回一个匿名内部类) - 继承这个类,并创建迭代器。这种方法适用于原本的类已经继承了其他类,所以不能再继承
AbstractCollection的情况下。
生成Iterator是将队列与消费队列的方法连接在一起耦合度的最小的方式,并且与实现Collection相比,它在序列上所施加的约束也少得多。
Foreach与迭代器
实现Iterable接口
目前我们知道的是,foreach语法可以用于数组和所有的Collection。Collection能使用Foreach语法,其实是因为Collection接口继承了Iterable接口,该接口中包含了一个能产生Iterator的iterator()方法,这里的Iterator被foreach用来遍历整个序列。所以如果我们创建了一个实现了Iterable接口的类,那么这个类其实也是可以使用foreach语法的。
import java.util.*;
public class IterableClass implements Iterable<String> {
protected String[] words = ("And that is how" + "we know the Earth to be banana-shaped.").split(" ");
public Iterator<String> iterator() {
return new Iterator<String>() {
private int index = 0;
@Override
public boolean hasNext() {
return index < words.length; }
@Override
public String next() {
return words[index++];
}
public void remove() { // remove()方法是可选方法,也可以不用写这一个方法
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) {
for(String s : new IterableClass())
System.out.print(s + " ");
}
}And that is howwe know the Earth to be banana-shaped.通过上面的例子我们知道,实现了Iterator接口中的hasNext()和next()这两个方法就足够了,因为foreach语法其实也就只依赖这两个方法。
使用Foreach语句遍历Map是比创建一个迭代器、再使用迭代器遍历更方便,还以上面的使用Entry遍历Map的方式为例,我们将使用迭代器遍历改为使用foreach遍历:
for(Map.Entry entry : m.entrySet())
System.put.print(entry.getKey() + "=" + entry.getValue() + ", ");不用使用者自己去创建迭代器遍历,这种写法无疑是更加简洁易读的。
ps: 实现Iterable接口是能使用foreach的充分条件,但不是必要条件,数组没有实现这个接口,却依然可以使用foreach。
适配器的使用
当有一个接口并需要另一个接口的时候,就可以使用适配器。下面的例子中,我们需要让一个ArrayList能使用foreach正序遍历,也能使用foreach倒序遍历。因为ArrayList本就已经实现了Iterable接口(能够然foreach对其正序遍历),且ArrayList的代码我们已经无法再改变,所以书中选择使用一个适配器类继承ArrayList,并在这个类中使用匿名内部类实现Iterable接口,从而达到能够使用foreach倒序遍历ArrayList的目的。
import java.util.*;
class ReversibleArrayList<T> extends ArrayList<T> {
public ReversibleArrayList(Collection<T> c) { super(c); }
public Iterable<T> reversed() {
return new Iterable<T>() {
@Override
public Iterator<T> iterator() {
return new Iterator<T>() {
int current = size() - 1;
public boolean hasNext() { return current > -1; }
public T next() { return get(current--); }
public void remove() {
throw new UnsupportedOperationException();
}
};
}
};
}
}
public class AdapterMethodIdiom {
public static void main(String[] args) {
ReversibleArrayList<String> ral = new ReversibleArrayList<String>(
Arrays.asList("To be or not to be".split(" ")));
for(String s : ral)
System.out.print(s + " ");
System.out.println();
for(String s : ral.reversed())
System.out.print(s + " ");
System.out.println();
}
}To be or not to be
be to not or be To上面的代码中其实使用了两个匿名内部类:
- 外面的内部类用来实现
Iterable接口,在这个接口中需要实现iterator()方法。 - 里面的内部类则是用来满足
iterator()方法所需要的返回类型,即Iterator<T>,内部类中需要实现这个接口,提供hasNext()和next()方法。