《Java编程思想》读书笔记 —— 第17章 容器深入研究
Back第十一章已经讲述了Java容器的基本使用,这一章的内容一半是关于理论,一般仍然是叙述容器的实用方法。
最近快开学了,但是我好像越来越懒了,原本的计划都被自己咕的差不多了。这一章内容我看了很多天,花的时间长是因为我看的不仔细且效率低下,而不是真的把它读得很通透……虽然说是深入研究容器,但是我觉得其实还不是特别深入,有关数据结构之类理论的部分还算是比较表面。即使作者写的是长篇大论,但是我觉得博客写出来应该不会很长。
填充容器
第十一章讲述容器的时候,填充容器一般是使用collection.addAll()或是Collections.addAll()这两种方法,其中后者更被推荐使用。这一章又介绍了新的填充容器的方法,分别是:
-
Collections.nCopies(int n, T o) 返回一个由n个o组成的
Collection对象javaList<String> list = new ArrayList<String>(Collections.nCopies(4, "Hello")); -
Collections.fill(List<? super T> list, T obj) 使用obj填充list
fill方法的作用更有限,因为它只能替换list中已经存在的元素。值得注意的是,两种方式都是用单个对象的引用填充Collection。
使用Abstract类
当我们想要创建自定义的容器类的时候,使用Abstract类是一种有效的解决方式。每个java.util容器都有自己的Abstract类,这些抽象类提供了容器的部分实现,用户需要做的是实现产生想要的容器所必须的方法。
下面是各个抽象类中未实现的方法:
- AbstractMap:
Set<Map.Entry<K,V>> entrySet() - AbstractCollection:
Iterator<E> iterator(),int size() - AbstractSet:
Iterator<E> iterator(),int size() - AbstractList:
E get(int index),int size()
书中提到了享元模式的概念,使用享元可以解决产生过多普通对象从而占用太多空间的问题。
享元模式使得对象的一部分可以被具体化,因此,与对象中的所有事物都包含在对象内部的不同,我们可以在更加高效的外部表中查找对象的一部分或整体(或者通过某些其他节省空间的计算来产生对象的一部分或整体)。
Map.Entry类的设计遵循了享元模式的理念,每个Map.Entry对象都只存储了索引,而不是实际的键和值,只有调用getKey()和getValue()的时候才会返回恰当的数据,这样使得entrySet的大小得以被控制。(实现entrySet的代码见467页)
Collection的功能方法
通用方法
| 通用方法 | 解释 |
|---|---|
| boolean add(T) | 添加元素(可选) |
| boolean addAll(Collection<? extends T>) | 添加参数中所有元素(可选) |
| void clear() | 移除容器中所有元素(可选) |
| boolean contains(T o) | 如果容器持有o,则返回true |
| Boolean containsAll(Collection<?> c) | 若容器包含c中所有元素,则返回true |
| boolean isEmpty() | 判断容器是否为空 |
| Iterator<T> Iterator() | 返回迭代器对象 |
| Boolean remove(Object) | 移除第一个指定对象(可选) |
| boolean removeAll(Collection<?>) | 移除参数序列中包含的元素(可选) |
| Boolean retainAll(Collection<?>) | 取交集 |
| int size() | 返回容器包含元素个数 |
| Object[] toArray() | 返回一个Object数组 |
| <T> T[] toArray(T[] a) | 返回指定类型的数组 |
上面的方法是每一个Collection对象都具备的。注意并不包括get()方法,因为Set是自己维护内部顺序的,随机访问对于Set没有意义。
可选操作
从上面的表格中我们可以总结出来一条规律,执行各种不同的添加和移除的方法在Collection接口中都是可选操作,可以实现,也可以不实现。如果我们不想实现某个操作只需要在它被调用时抛出异常UnsupportedOperationException。
可选操作是为了放置设计中出现的“接口爆炸”的情况,对于接口中的众多方法,我们可以选择暂时先不实现,需要 / 学会怎么写 的时候再回头实现。
示例:有关Arrays.asList()方法:
Arrays.asList(T... a)接收一个对象序列并返回一个List,因为这个List基于一个固定大小的数组,所以它仅支持不会改变数组大小的操作。如果我们试图添加或删除元素,则会获得一个UnsupportedOperationException异常。
如果想要改变asList()产生的List,当然只能另开辟一个可以改变的List,可以将asList()的结果作为构造器参数、使用collection.addAll()方法、转化为数组使用Collections.addAll()方法:
List<String> list = Arrays.asList("A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" "));
// list.add("Hello"); // UnsupportedOperationException
// 方法一:将list作为参数传入list2的构造器
List<String> list2 = new ArrayList<String>();
// 方法二:使用collection.addAll()
list2.addAll(list);
// 方法三:使用Collections.addAll()(前提是先把list转化为数组)
Collections.addAll(list2, list.toArray(new String[0]));
// 以上三种方法任选一种即可
list2.add("hhh");
System.out.println(list2);List的功能方法
使用List最多使用的是添加元素(add)、访问元素(get)和使用其迭代器(iterator),下面是List中一些方法我认为需要记一下的细节:
- addAll() 不仅仅可以只接收一个collection,将其添加在末尾,也有addAll(int index, Collection<? extends E> c)的形式,索引值index规定了添加的起始位置。
- String类中的indexOf()方法有以下四种重载形式,可以选择从某个位置开始查找字符或子串,但是List中的indexOf方法只有一种形式,无法规定startIndex。
Set和存储顺序
在三种常用Set中,HashSet和LinkedHashSet使用散列存储,TreeSet使用树形存储。
HashSet和LinkedHashSet中,判断元素是否相同时,是先比较hashCode()方法的返回值,再使用equals()方法比较。而TreeSet则是根据Comparable接口,如果使用把没有实现Comparable的类型存入TreeSet,则会得到异常。
对于Comparable和Comparator的使用,在第16章数组中已经介绍过了,这里不再赘述。
TreeSet实现了SortedSet接口,所以有一些较为特殊的方法可供使用:
| Modifier and Type | Method | Description |
|---|---|---|
Comparator |
comparator() |
Returns the comparator used to order the elements in this set, or null if this set uses the natural ordering of its elements. |
E |
first() |
Returns the first (lowest) element currently in this set. |
SortedSet |
headSet(E toElement) |
Returns a view of the portion of this set whose elements are strictly less than toElement. |
E |
last() |
Returns the last (highest) element currently in this set. |
default Spliterator |
spliterator() |
Creates a Spliterator over the elements in this sorted set. |
SortedSet |
subSet(E fromElement, E toElement) |
Returns a view of the portion of this set whose elements range from fromElement, inclusive, to toElement, exclusive. |
SortedSet |
tailSet(E fromElement) |
Returns a view of the portion of this set whose elements are greater than or equal to fromElement. |
由于元素有序,所以对集合的截取就是一件有意义的事情。
理解Map
| 类 | 描述 |
|---|---|
| HashMap | 基于散列表实现,插入和查询键值对的开销是固定的,可以通过构造器设置容量和负载因子,以调整容器性能。 |
| LinkedHashMap | 访问比HashMap慢一点,但是迭代访问会更快。 |
| TreeMap | 实现了SortedMap接口,具有和上文中SortedSet相似的功能呢。 |
| WeakMap | 如果映射之外没有引用指向某个键,则该键可被垃圾回收器回收。 |
| ConcurrentHashMap | 线程安全,不涉及同步加锁。 |
| IdentityHashMap | 使用==代替equals()对键进行比较的散列映射。用于解决特殊问题。 |
任何键必须有equals()方法,使用散列存储必需实现hashCode(),使用树型存储则必须实现Comparable接口。
1. equals()方法需要满足的条件
在离散数学中曾经学到过等价关系,equals()方法需要确保它判断的是两个对象是否等价。等价关系有三个条件:
- 自反性:对任意x,
x.equals(x) == true - 对称性:若
x.equals(y) == true,则有y.equals.(x) == true - 传递性:若
x.equals(y) == true且y.equals(z) == true,则有x.equals(z) == true
书中给出了equals()方法应该满足的5个条件,上面有3种,还剩下两种:
- 一致性:如果x和y都未改变,那么无论进行多少次equals比较,结果都不会改变
- 对于任何不是null的x,
x.equas(null)一定返回false
下面是一个典型的自定义equals():
public boolean equals(Obejct o) {
return o instanceof MyClass &&
(number == ((MyClass)o).number);
}原本我的意识里只有直接判断属性是否相同,但是现在看来Instanceof是必不可少的。
2. 关于散列
书中对于TreeMap的原理基本没提,对于散列提到了一些。
使用一个散列函数将值的索引放在某个数组中,使用外部链接的方式处理冲突。然后是对散列表设计的建议:
- 为使散列分布均匀,桶的数量通常使用质数
- Java散列函数使用2的整数次方,而不是取余,因为取余操作开销较大。
对于如何写hashCode(),第496页有基本的指导(但是我没看懂)。
3. Map的性能因子
- 容量:表中桶的位数
- 初始容量:表创建时所拥有的桶位数
- 尺寸:表中当前存储的项数
- 负载因子:HashMap和HashSet都允许有指定负载因子的构造器,当负载情况达到该负载因子的水平时,容器将自动增加其容量(桶位数),实现方式是使容量大概加倍,并重新将现有对象分布到新的桶位集中(这被称为再散列)。HashMap的默认负载因子是0.75,即桶达到四分之三满时,才进行再散列。
如果我们知道HashMap中存储多少项,创建一个具有恰当大小的初始容量可以避免自动再散列的开销。
HashMap有下面几种构造器,可以指定初始容量和负载因子:
| Constructor | Description |
|---|---|
| HashMap() | Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75). |
| HashMap(int initialCapacity) | Constructs an empty HashMap with the specified initial capacity and the default load factor (0.75). |
| HashMap(int initialCapacity, float loadFactor) | Constructs an empty HashMap with the specified initial capacity and load factor. |
| HashMap(Map<? extends K,? extends V> m) | Constructs a new HashMap with the same mappings as the specified Map. |
Collections实用方法
1. 一些方法记录:
-
Collections.disjoint(Collection<?> c1, Collection<?> c2) 判断两个Collection是否不相交
-
Collections.singletonList(T o) 返回一个只包含o的List,且该List是不可变的(singleton方法则是返回Set)
-
Collections.rotate(List<?> list, int distance) 每个元素后移distance个单位(把list当做一个环形列表)
-
Collections.frequency(Collection<?> c, Object o) 返回序列中o的个数
2. List排序
List的排序使用Collections.sort()方法,用法和Arrays.sort()相同。
3. 只读Collection / Map
使用的方法:Collections.unmodifiableCollection(), Collections.unmodifiableList(), Collections.unmodifiableSet(), Collections.unmodifiableMap()
这些方法都是接收一个Collection对象,返回一个相应的只读对象。
4. 快速报错
如果有一个进程正在操作一个容器,此时另一个进程试图修改这个容器的内容,会抛出ConcurrentModificationException异常。
持有引用
没看明白。
首先需要明确怎么样的对象是可获得的(reachable):当仍有普通的引用指向(无论是直接还是有更多中间链接)对象的时候,这个对象是可获得的。这时垃圾回收器就不能将这个对象释放,因为它仍然为我们的程序所用。
如果想持有某个对象的引用,希望以后还能访问到该对象,但是也希望能够允许垃圾回收器释放它,这时就需要使用Reference对象。
由强到弱排列的Reference类:
- SoftReference 用以实现内存敏感的高速缓存
- WeakReference 为了实现“规范映射”
- Phantomreference 用以调度回收前的清理工作,比Java终止机制更加灵活
后面的示例代码运行起来很迷,这块知识还是以后再说……
Java 1.0/1.1的容器
-
Vector:Collection和List出现之前,Vector是唯一可以自我扩展的序列,但是缺点太多,已被弃用。
-
Enumeration:迭代器的前身,只有以下两个方法
- boolean hasMoreElements()
- Object nextElement()
使用Vector的
elements()方法或Collections.enumeration()产生一个Enumeration对象。 -
Stack:直接继承自Vector,不仅Vector设计的不好,使用继承而不是组合也是相当错误的设计。
-
BitSet:作为开关使用,现在基本被EnumSet代替了,每个元素使用64位表示(支持所有大小的整型数)
javaBitSet bs = new BitSet(); bs.set(0); bs.set(1); bs.set(3); // bs.clear(0); System.out.println(bs.get(3)); System.out.println(bs.nextSetBit(1)); System.out.println(bs);texttrue 1 {0, 1, 3}
总结
网上只能找到这张不是有水印的图,是书中第17章第一节的插图:
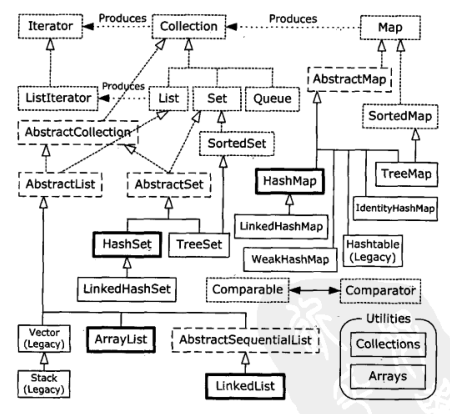
这章还是讲了很多方法的使用,对于Set和Map的原理进行了一定程度的探讨,关于排序的部分,由于和前一章内容基本重合,就没有多写。书中花了很大心思写了一个针对容器的测试框架,由于依赖之前的类我就没有照着敲一遍,用事实向读者展示了各容器在进行多种操作时的速度差异。
书中代码很多,但是我觉得没有很大必要贴出来(但是很多代码我还是有很认真对着书敲出来的)。
然后是书上看的不太仔细的地方:享元模式的实现、Generator使用、作者对容器的测试(代码敲了大概一半,但是我更多的只是看了结论)、Reference(我觉得书上说的也不太清晰)。希望以后自己可以捡起来这些没有学好的东西。